从CPU运行到函数调用 计算机程序执行的微观探秘
在计算机科学的世界里,程序的执行并非魔法,而是一系列精密、有序的步骤。理解从中央处理器(CPU)的常规运行到函数调用的具体过程,是深入编程和系统设计的关键。本文将以通俗的方式,解析这一微观旅程。
一、 CPU的日常:取指、解码、执行
CPU是计算机的“大脑”,其核心工作循环可以概括为三个步骤:
- 取指(Fetch):CPU从内存中,按照程序计数器(PC)指向的地址,读取下一条要执行的指令。
- 解码(Decode):控制单元对取到的指令进行解析,识别出需要执行什么操作(如加法、数据移动)以及操作数在哪里。
- 执行(Execute):算术逻辑单元(ALU)或其他相关部件根据解码结果,实际执行该指令,比如完成一次计算或将数据写入寄存器。
执行完毕后,程序计数器会自动更新,指向下一条指令的地址,循环就此周而复始,推动程序顺序执行。
二、 当遇到函数调用:流程的“岔路口”
当CPU顺序执行的指令是一条“函数调用”(例如C语言中的 call func 或高级语言中的 func())时,这个平静的循环将被打破,流程需要转向另一个独立的代码块。这个过程远比跳转指令复杂,因为它涉及“如何回来”以及“如何保持现场”。
一个完整的函数调用过程,可以分解为以下几个关键阶段:
1. 调用前:参数传递与返回地址压栈
在跳转到函数代码之前,调用者需要做好准备:
- 参数传递:按照调用约定(如C语言的从右向左压栈),将函数所需的参数值放入指定的寄存器或压入栈(Stack) 这一内存区域。
- 保存返回地址:将函数调用指令之后的那条指令的地址(即“返回地址”)压入栈中。这是函数执行完毕后,CPU能知道回到哪里的关键。
2. 跳转与现场保护
- CPU更新程序计数器(PC),跳转到被调用函数的起始地址,开始执行函数体的指令。
- 函数开头通常会执行序言(Prologue),将当前函数需要使用的某些寄存器(称为“调用者保存寄存器”)的值压栈保存。这保护了调用者的运行现场,确保函数返回后调用者能无缝衔接。
3. 函数体的执行
- 此时,CPU就像执行普通代码一样,在函数体内进行取指、解码、执行的循环。函数可以通过栈指针(SP)的相对偏移来访问传入的参数和自身的局部变量(这些局部变量也在栈上分配空间)。
4. 返回前:清理与恢复现场
- 函数执行到 return 语句时,会将返回值存入约定的寄存器(如EAX/RAX)。
- 接着执行尾声(Epilogue),恢复之前保存的寄存器值,并调整栈指针,释放本函数用于局部变量和保存现场的空间。
5. 返回与后续执行
- 执行一条返回指令(如 ret)。该指令会从栈顶弹出之前保存的返回地址,并让CPU跳转到该地址继续执行。
- 调用者根据调用约定,可能需要进一步调整栈指针以清理传入参数的空间,然后从返回值寄存器中获取结果,继续向下执行。
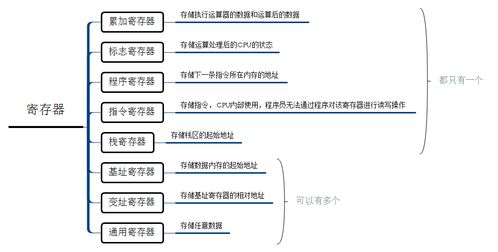
三、 核心支撑:栈(Stack)的关键角色
纵观整个过程,栈这一“后进先出”的内存数据结构起到了核心的“记事本”和“工作台”作用。它按顺序记录了:返回地址、调用者帧指针、参数、局部变量等。每一次函数调用,都在栈上分配一个独立的区域,称为“栈帧”。栈指针(SP)和帧指针(FP)寄存器共同管理着这些栈帧的边界,使得嵌套函数调用和返回能井然有序地进行。
###
从CPU的基础运行周期到复杂的函数调用,计算机通过硬件(PC、SP寄存器)与软件(调用约定、栈管理)的精密配合,实现了代码的模块化执行与流程控制。理解这个过程,不仅能帮助程序员写出更高效、bug更少的代码(例如理解栈溢出),也是学习操作系统、编译原理等更深层知识的坚实基石。这正如一位名为“littlehero 121”的CSDN博主可能分享的那样:窥探这微观世界的运行机制,是每个编程爱好者成长为真正“高手”的必经之路。
如若转载,请注明出处:http://www.myeomn.com/product/49.html
更新时间:2026-06-19 12:56:51